Introduction: The Need for Speed in AI Knowledge Retrieval
In the world of generative AI, latency and accuracy are everything. RAG (Retrieval-Augmented Generation) has been the go-to method for combining external knowledge with large language models (LLMs). However, as demands for faster and more reliable response generation increase, the spotlight has shifted to Cache-Augmented Generation (CAG)—a simpler, faster, and more reliable alternative.
Imagine loading all the knowledge your model needs before you even ask a single question. No delays, no retrieval errors, and no complex architectures. CAG makes this possible, revolutionizing how we think about AI-powered generation tasks.
RAG: Retrieval-Augmented Generation

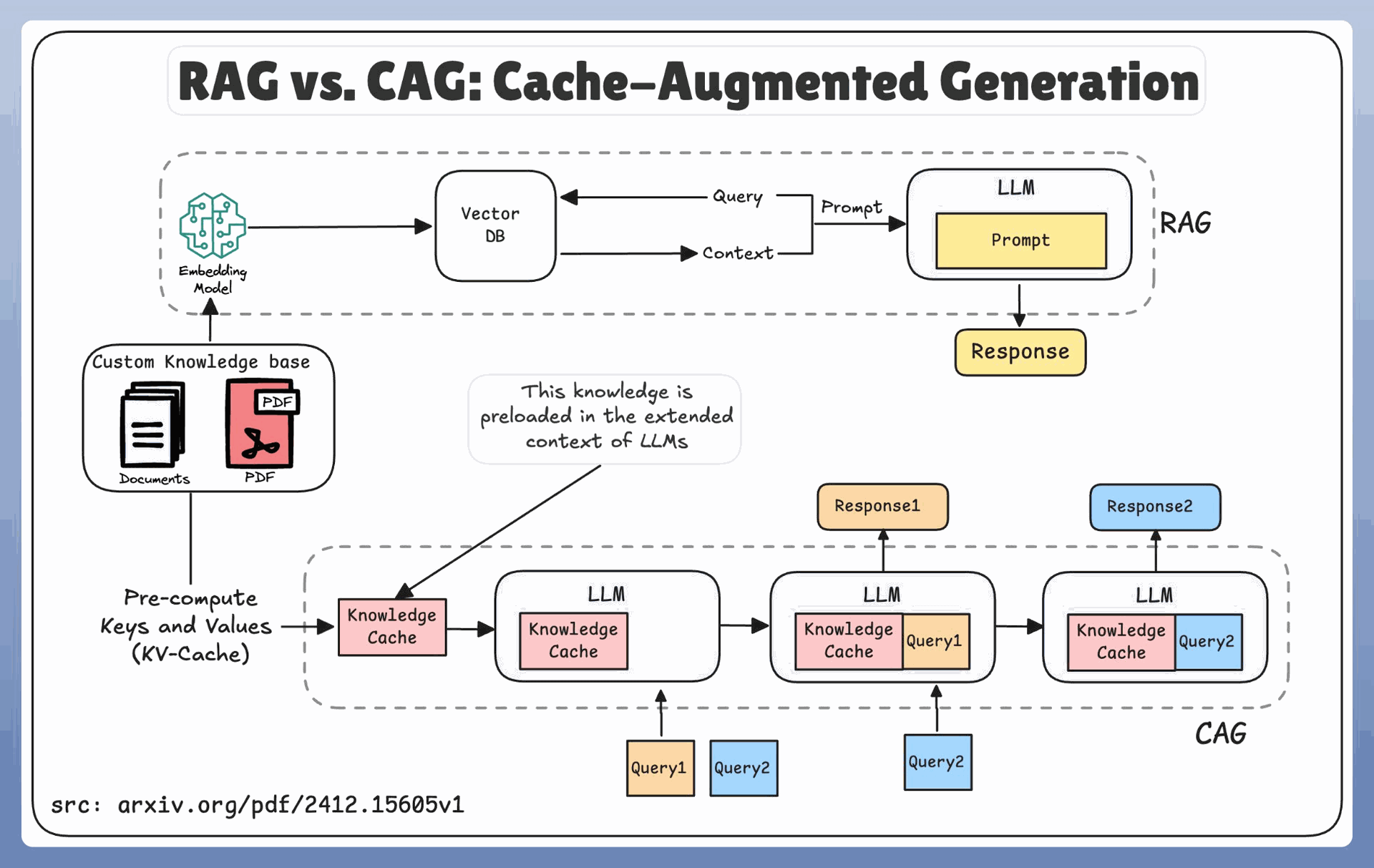
RAG relies on real-time retrieval to provide context for LLMs. Here’s a typical RAG workflow:
- A query is sent to a Vector Database connected to a custom knowledge base (e.g., PDFs, documents).
- The retriever model fetches the most relevant documents.
- The retrieved documents are used to build a context for the LLM, which generates a response.
While RAG works well for dynamic knowledge bases, its downsides include latency due to real-time retrieval and potential errors in selecting the right documents.
CAG: Cache-Augmented Generation

CAG introduces a paradigm shift by replacing real-time retrieval with preloaded knowledge. Here’s how it works:
- Knowledge from documents or PDFs is precomputed into a Key-Value Cache (KV-Cache).
- This cache is loaded into the extended context of the LLM before any queries are made.
- The LLM generates responses directly from the preloaded context without relying on external retrieval during inference.
This approach simplifies the workflow and eliminates delays caused by real-time querying.
Key Benefits of Cache-Augmented Generation
1️⃣ Zero Latency
All knowledge is preloaded, so there’s no waiting for retrieval pipelines to fetch information.
2️⃣ Higher Accuracy
With no need for real-time retrieval, CAG avoids errors caused by ranking or document selection mistakes.
3️⃣ Simplified Architecture
Say goodbye to complex retrieval pipelines. CAG removes the need for a separate retriever model.
4️⃣ Consistent and Reliable Responses
The preloaded context ensures uniformity in responses across similar queries.
5️⃣ Faster Inference
Once cached, the response generation is significantly faster than RAG-based systems.
Challenges of CAG
No approach is perfect, and CAG has its limitations:
- Static Knowledge: Since the KV-cache is precomputed, CAG isn’t suitable for dynamic or frequently updated data.
- LLM Context Constraints: The effectiveness of CAG is limited by the maximum token length of the LLM. Handling large datasets in the cache can be challenging.
When to Choose CAG Over RAG?
Here’s when CAG makes sense:
- Static Knowledge Bases: Ideal for FAQs, customer support systems, and scenarios where the knowledge base doesn’t change frequently.
- High-Speed Applications: If latency is a critical factor, CAG is the way to go.
- Simpler Systems: Use CAG to reduce architectural complexity and avoid retriever-related errors.
The Future of Knowledge-Augmented AI
As LLMs evolve, token limits will expand, and caching strategies will become more efficient. CAG is a step toward a future where knowledge integration is seamless, accurate, and lightning-fast. However, for real-time or dynamic data, RAG will remain relevant, making it essential to choose the right approach for the task at hand.
RAG vs. CAG – A New Era of Knowledge-Augmented AI